Hal Shaw Hal Shaw
0 Course Enrolled • 0 Course CompletedBiography
Valid DP-600 Test Papers - Latest DP-600 Test Format
BTW, DOWNLOAD part of RealVCE DP-600 dumps from Cloud Storage: https://drive.google.com/open?id=1Rs2fc7pQ0EyDGeEo2FFrwQxNSJPthwj4
The pressure is not terrible, and what is terrible is that you choose to evade it. You clearly have seen your own shortcomings, and you know that you really should change. Then, be determined to act! Buying our DP-600 exam questions is the first step you need to take. Only with our DP-600 Practice Guide, then you will totally know your dream clearly and have enough strenght to make it come true. Our DP-600 learning materials have became a famous brand which can help you succeed by your first attempt.
The RealVCE Microsoft DP-600 online practice exam is browser-based and accessible via any browser including Firefox, MS Edge, Safari, Opera, Chrome, and Internet Explorer. This format is also embedded with multiple Microsoft DP-600 Practice Exam and all specs of the desktop software. You can easily adjust time and questions in all Implementing Analytics Solutions Using Microsoft Fabric online Practice Exam.
>> Valid DP-600 Test Papers <<
Top-Selling DP-600 Realistic Practice Exams
You can avail all the above-mentioned characteristics of the desktop software in this web-based Microsoft DP-600 practice test. While you appear in the Microsoft DP-600 real examination, you will feel the same environment you faced during our Microsoft DP-600 practice test.
Microsoft DP-600 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
Microsoft Implementing Analytics Solutions Using Microsoft Fabric Sample Questions (Q87-Q92):
NEW QUESTION # 87
You have a Fabric tenant that contains a warehouse. The warehouse uses row-level security (RLS).
You create a Direct Lake semantic model that uses the Delta tables and RLS of the warehouse.
When users interact with a report built from the model, which mode will be used by the DAX queries?
- A. Dual
- B. Import
- C. Direct Lake
- D. DirectQuery
Answer: D
Explanation:
Row-level security only applies to queries on a Warehouse or SQL analytics endpoint in Fabric.
Power BI queries on a warehouse in Direct Lake mode will fall back to Direct Query mode to abide by row-level security.
https://learn.microsoft.com/en-us/fabric/data-warehouse/row-level-security
NEW QUESTION # 88
You have a Fabric tenant that contains a semantic model. The model contains data about retail stores.
You need to write a DAX query that will be executed by using the XMLA endpoint The query must return a table of stores that have opened since December 1,2023.
How should you complete the DAX expression? To answer, drag the appropriate values to the correct targets.
Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Answer:
Explanation:
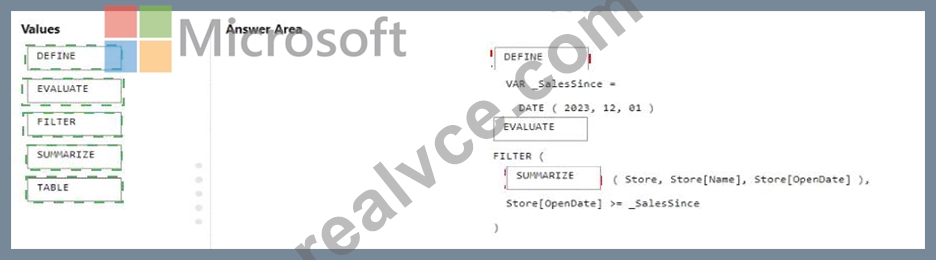
Explanation:
The correct order for the DAX expression would be:
* DEFINE VAR _SalesSince = DATE ( 2023, 12, 01 )
* EVALUATE
* FILTER (
* SUMMARIZE ( Store, Store[Name], Store[OpenDate] ),
* Store[OpenDate] >= _SalesSince )
In this DAX query, you're defining a variable _SalesSince to hold the date from which you want to filter the stores. EVALUATE starts the definition of the query. The FILTER function is used to return a table that filters another table or expression. SUMMARIZE creates a summary table for the stores, including the Store[Name] and Store[OpenDate] columns, and the filter expression Store[OpenDate] >= _SalesSince ensures only stores opened on or after December 1, 2023, are included in the results.
References =
* DAX FILTER Function
* DAX SUMMARIZE Function
NEW QUESTION # 89
You have an Azure Data Lake Storage Gen2 account named storage! that contains a Parquet file named sales.
parquet.
You have a Fabric tenant that contains a workspace named Workspace1.
Using a notebook in Workspace1, you need to load the content of the file to the default lakehouse. The solution must ensure that the content will display automatically as a table named Sales in Lakehouse explorer.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
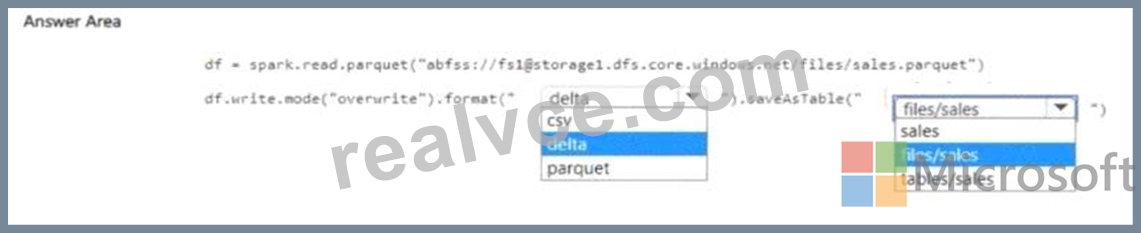
Answer:
Explanation:
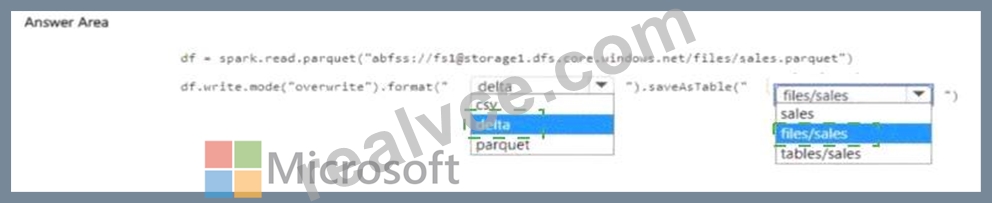
Explanation:

Step 1 - Read the Parquet file into a DataFrame
df = spark.read.parquet("abfss://fs1@storage1.dfs.core.windows.net/files/sales.parquet") This correctly loads the Parquet data into Spark.
Step 2 - Write into the Lakehouse as a managed table
If we want the result to be registered as a Lakehouse table and automatically appear in Lakehouse Explorer, we must:
Write the data in delta format (because Fabric Lakehouse tables are Delta tables).
Save the table under the tables folder, not files.
So the correct code is:
df.write.mode("overwrite").format("delta").saveAsTable("tables/sales")
Final Answer:
Format: delta
SaveAsTable Path: tables/sales
References:
Lakehouse tables in Microsoft Fabric
Save DataFrame as Delta Table in Spark
# Answer Selection:
First dropdown # delta
Second dropdown # tables/sales
NEW QUESTION # 90
You have a Fabric eventhouse that contains a KQL database. The database contains a table named TaxiData that stores the following data.

You need to create a column named FirstPickupDateTime that will contain the first value of each hour from tpep_pickup_datetime partitioned by payment_type.
NOTE: Each correct selection is worth one point.

Answer:
Explanation:

Explanation:

NEW QUESTION # 91
You have a Fabric warehouse that contains two tables named DimDate and Trips.
DimDate contains the following fields.
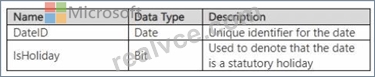
Trips contains the following fields.

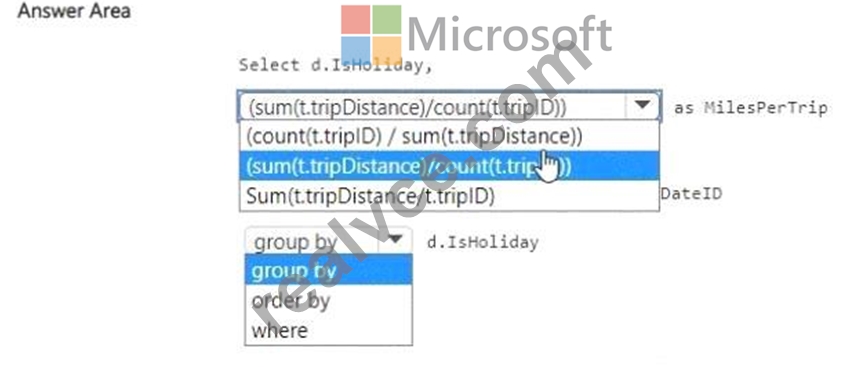
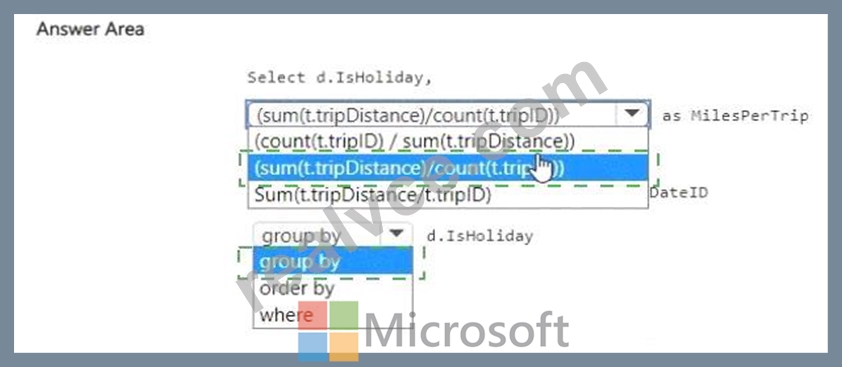
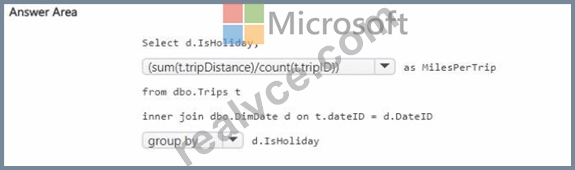
You need to compare the average miles per trip for statutory holidays versus non-statutory holidays.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Comprehensive Detailed Explanation
Step 1: Requirement
We need to compare the average miles per trip for:
Statutory holidays (when IsHoliday = 1)
Non-statutory holidays (when IsHoliday = 0)
Step 2: Formula for average miles per trip
Average miles per trip = total miles ÷ number of trips
Total miles # SUM(t.tripDistance)
Number of trips # COUNT(t.tripID)
So the calculation is:
(SUM(t.tripDistance) / COUNT(t.tripID)) AS MilesPerTrip
Step 3: Grouping
We need a comparison by holiday status.
So we must group the results by:
GROUP BY d.IsHoliday
This ensures we get two rows: one for IsHoliday = 1 and one for IsHoliday = 0.
Step 4: Final Query
SELECT
d.IsHoliday,
(SUM(t.tripDistance) / COUNT(t.tripID)) AS MilesPerTrip
FROM DimDate d
INNER JOIN Trips t ON d.DateID = t.DateID
GROUP BY d.IsHoliday;
Why This is Correct
The formula ensures average miles per trip.
Grouping ensures comparison between holidays vs non-holidays.
Efficient aggregation, minimal computation.
References
Aggregate functions in T-SQL
GROUP BY clause
NEW QUESTION # 92
......
For added reassurance, we also provide you with up to 1 year of free Microsoft Dumps updates and a free demo version of the actual product so that you can verify its validity before purchasing. The key to passing the Microsoft DP-600 exam on the first try is vigorous Implementing Analytics Solutions Using Microsoft Fabric (DP-600) practice. And that's exactly what you'll get when you prepare from our Implementing Analytics Solutions Using Microsoft Fabric (DP-600) practice material. Each format of our DP-600 study material excels in its own way and serves to improve your skills and gives you an inside-out understanding of each exam topic.
Latest DP-600 Test Format: https://www.realvce.com/DP-600_free-dumps.html
- Microsoft DP-600 Exam Questions are Real, Valid, and Verified by Experts 🍓 Easily obtain free download of ➡ DP-600 ️⬅️ by searching on ▷ www.troytecdumps.com ◁ 🐮DP-600 Latest Braindumps Ppt
- Practice DP-600 Exam 🌷 DP-600 Reliable Test Syllabus 🦎 DP-600 Latest Dumps Questions 🎱 Search on ➥ www.pdfvce.com 🡄 for ➤ DP-600 ⮘ to obtain exam materials for free download 📩DP-600 Actualtest
- Simulated DP-600 Test 🥶 DP-600 Passing Score Feedback 😻 Valid DP-600 Exam Camp 💕 Search for 「 DP-600 」 on 【 www.examcollectionpass.com 】 immediately to obtain a free download 🦞Reliable DP-600 Real Test
- Updated and Error-free DP-600 Exam Practice Test Questions 🔮 Search for ✔ DP-600 ️✔️ and download it for free immediately on 《 www.pdfvce.com 》 ▶DP-600 New Exam Braindumps
- Latest DP-600 Test Practice 💰 Most DP-600 Reliable Questions 🔑 Most DP-600 Reliable Questions 🕥 Search for ⏩ DP-600 ⏪ and obtain a free download on ➽ www.vceengine.com 🢪 🥚DP-600 Exam Questions
- DP-600 Passing Score Feedback 💠 Reliable DP-600 Real Test 🐠 Exam DP-600 Demo 🙎 Search for ⮆ DP-600 ⮄ and obtain a free download on “ www.pdfvce.com ” 👄Reliable DP-600 Real Test
- Exam DP-600 Demo ☘ Exam DP-600 Demo 😋 Exam DP-600 Demo 🌎 Open website ✔ www.exam4labs.com ️✔️ and search for ➡ DP-600 ️⬅️ for free download 🍑DP-600 Passing Score Feedback
- Valid DP-600 Test Papers - Quiz 2026 DP-600: First-grade Latest Implementing Analytics Solutions Using Microsoft Fabric Test Format ❔ Open ⏩ www.pdfvce.com ⏪ and search for 【 DP-600 】 to download exam materials for free 👯DP-600 Latest Braindumps Ppt
- New DP-600 Test Objectives 🐼 Latest DP-600 Exam Online 🟣 DP-600 Passing Score Feedback 🍦 Download ⏩ DP-600 ⏪ for free by simply entering ➠ www.prepawayete.com 🠰 website 🔃Latest DP-600 Study Materials
- DP-600 Latest Braindumps Ppt 📹 Simulated DP-600 Test 😩 DP-600 New Exam Braindumps 🗾 Search for ⏩ DP-600 ⏪ and download it for free on ➡ www.pdfvce.com ️⬅️ website 🌁Reliable DP-600 Real Test
- 100% Pass Quiz Microsoft - Professional DP-600 - Valid Implementing Analytics Solutions Using Microsoft Fabric Test Papers 🧿 Search for ⮆ DP-600 ⮄ and obtain a free download on 《 www.testkingpass.com 》 ➡️DP-600 Actualtest
- issuu.com, www.stes.tyc.edu.tw, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, linkdirectory724.com, www.stes.tyc.edu.tw, onlybookmarkings.com, onlybookmarkings.com, www.stes.tyc.edu.tw, agnesckoh275671.ssnblog.com, bookmarkingfeed.com, Disposable vapes
BTW, DOWNLOAD part of RealVCE DP-600 dumps from Cloud Storage: https://drive.google.com/open?id=1Rs2fc7pQ0EyDGeEo2FFrwQxNSJPthwj4